
Datadog-Powered DevOps: Monitoring eCommerce Systems Without the Blind Spots

Checkout delays, silent drop-offs, alerts that don’t point to real issues… You’ve likely seen how monitoring gets harder as traffic grows and systems branch out. Third-party APIs fail quietly, and incident response takes longer than it should. That’s because fragmented tools don’t give you a full picture, especially during peak load.
In this article, you’ll see how Datadog-powered DevOps can help you connect the dots, reduce noise, and track application performance at every layer. But first, let’s see what makes monitoring so difficult at scale.
Key Monitoring Challenges in eCommerce
We don’t need to tell you that as your eCommerce traffic grows and systems get more distributed, keeping everything stable becomes harder. Monitoring issues can impact your uptime, revenue, customer trust, and team focus.
Hence, here are the common problems that stand in your way:
- Checkout failures with no clear root cause: You’ve likely dealt with sudden drops in conversion where everything “looks fine” from the backend. But dig deeper, and you’ll see payment errors, browser quirks, or JavaScript issues blocking orders. Alexander Jarvis notes that 40% of these failures come from compatibility issues across devices or browsers, while 18% trace back to poor form handling.
- Third-party app outages (e.g., payment APIs) you don’t control: Stripe, PayPal, tax calculators, address validators… any of these can break during peak hours. If you’re not monitoring external event types or running browser checks, you’re missing a major gap in your system’s reliability.
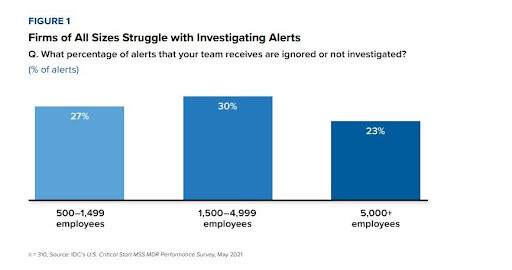
- Alert fatigue or missing critical incidents: Too many alerts and not enough context is why, according to IDC in 2021, companies ignore around 23–30% of alerts. That creates noise, but worse, it hides the real issues that matter.
- Post-deployment bugs only spotted by users: QualityHive found that 85% of website bugs are caught by users after launch. What that tells us is that even solid CI/CD + synthetic tests can’t fully simulate messy, diverse, real-world usage. So, combining them with observability, customer feedback loops, and real-user monitoring (RUM) is what closes the gap. Of course, synthetic tests and CI/CD don’t inherently fail to represent reality. A well-architected CI/CD pipeline can include real-world scenarios (e.g., end-to-end tests, canary deployments, chaos engineering). It’s not the type of testing that’s the problem; it’s the scope and depth.
Why eCommerce Monitoring Breaks at Scale
Monitoring tends to fall behind because your architecture expands like a city (fast, messy, and usually without updated maps). These are the main causes:
- Tech sprawl: You’re juggling headless stacks, microservices, and legacy systems across global traffic. Each part might be working fine on its own, but they’re not always in sync.
- Visibility gaps: Too many tools and dashboards mean no central view. Grafana’s 2023 survey shows that 31% of teams use four or five observability platforms. Some even use over ten. That dilutes focus and slows down response.

Source: 3rd annual Observability Survey by Grafana Labs
- Pressure to move fast: Speed wins in commerce. But rapid cycles, especially when teams struggle to stay on schedule, can increase the risk of overlooked edge cases. When timelines slip, testing windows get squeezed, and teams often focus on core functionality at the expense of rare or complex scenarios. In fact, ING’s 2019 study shows that 76% of teams using rapid release cycles are releasing on schedule less than half the time, compared to 60% for slower-release teams, even if fast-release teams should theoretically have better automation and testing discipline. Basically, velocity under pressure doesn’t always translate to smooth execution or complete coverage.
Now, that’s where a Datadog-powered approach gives you the visibility and control to stay ahead.
What “Datadog-Powered DevOps” Actually Means for eCommerce
“Datadog-Powered DevOps” means connecting your data, teams, and systems in one place so you can catch issues early and act fast. These are the core capabilities that make that possible across fast-moving eCommerce environments.
Metrics, Logs, and Traces Working Together
Datadog gives you full visibility into how your eCommerce stack behaves at every level and in real time. It collects telemetry data from 100% of your traffic, so you’re always sure which requests matter.
With logs tied to traces and metrics, you can troubleshoot without switching tools. For example, a sudden spike in cart abandonment tied to API latency gets flagged immediately.
Using On-Call, your team can trace it to a recent deployment and roll it back within minutes. This normally stops the revenue loss before it spreads.
Deep Integration Across Your Stack
From CI/CD pipelines and cloud platforms to payment processors and customer-facing UIs, Datadog links everything. Its Stripe integration gives you over 200 real-time metrics, from transaction volumes to error rates. So when Stripe errors surge, you’ll see it on a live dashboard, not from a customer support ticket.
If you have deployment issues, APM Watchdog catches broken releases by surfacing latency spikes or error rates. You can jump straight to the root cause using the linked traces, without manually filtering through logs.
And it’s not just theoretical.
Datadog’s impact across retail and commerce is already clear. Over 16,000 POS devices run with full observability, 90 million users are supported monthly, and some teams report up to 50% savings on cloud resources.
Automation That Flags What Matters
Datadog also takes a load off your team by automating problem detection. Synthetic Monitoring runs code-free tests against internal and third-party APIs. It spots silent failures in supply chain endpoints before your users ever notice.
That’s how teams like Compass cut their mean time to resolution from over two hours to just 16 minutes. And with anomaly detection, auto-tagging, and SLO alerts, you don’t need to manually tune thresholds every week. You’ll stay ahead of issues without drowning in false positives.
Now, let’s see how to apply that setup across your commerce stack step by step.
How to Monitor eCommerce with Datadog: A Step-by-Step Plan
You probably already know that default dashboards and plug-and-play scripts rarely cover what actually matters in production. They’re a starting point, not a strategy, especially when customer experience is on the line. These are the steps that help you build real coverage across your commerce stack.
1. Map Your Architecture and Transaction Flow
Start with a clear picture of your architecture, such as microservices, APIs, cloud resources, third-party integrations, and deployment gates. From there, map the flow of a user transaction end-to-end, from product view to payment confirmation. This matters because that baseline helps you pinpoint where to instrument and where your blind spots are.
2. Instrument Critical Paths (Checkout, Payment, Fulfillment)
Not every service needs deep visibility, but checkout does. The same goes for payment flows and fulfillment APIs. Use distributed tracing to connect frontend activity to backend services like Stripe, Shopify, or internal inventory systems. That way, when something breaks, you know exactly which service or integration is responsible.
3. Set Up Multi-Layer Alerts (Infrastructure → App → Business Events)
Start at the base: host health, memory, network. From there, layer in application metrics like error rates and API key misfires. On top of that, add business event tracking, such as drop in order volume, increase in cart abandonment, missed SLA on a shipping API. Each step builds context, and each layer tells a different part of the story.
4. Connect to Your CI/CD (e.g., GitHub Actions, Jenkins)
Tie your monitoring setup to every step in your release pipelines. That means you should track deploy events, flag increased latency after a release, and monitor rollback behavior. This way, you catch risky code before users feel it.
5. Create Dashboards for DevOps, Support, and Product Teams
Use Datadog Notebooks and custom views for each team. For example, DevOps teams need system metrics. Meanwhile, support teams need user error visibility. At the same time, Product teams care about behavior across features or regions. Role-specific views eliminate inessential metrics that increase the clutter to focus your response.
But even with the right setup, it’s easy to fall into a few common traps.
Common Mistakes eCommerce Teams Make with Datadog
Even mature teams can fall into habits that limit what Datadog can actually do for them. These are the common gaps that slow down your response time, inflate your costs, or miss real business signals:
- Treating Datadog like just another dashboard tool: If you’re only looking at static widgets, you’re missing the value. Datadog thrives on correlations between traces, logs, metrics, and deploys. Without those links, dashboards become dead ends during incidents.
- Over-alerting or not setting SLOs: Too many teams still treat alerts as one-size-fits-all. That’s how you end up with noise. Without clear SLOs, you don’t know what matters, and engineers start ignoring real issues.
- Forgetting cost optimization: High-cardinality metrics and raw log ingestion can balloon costs fast. Without filters or sampling strategies, even simple services can rack up unexpected charges. This is not just a budget issue because it also adds unnecessary complexity to your data.
- Not aligning monitoring to actual business outcomes: A common pitfall is stopping at infrastructure visibility. You might have clear metrics on server load or uptime, but no direct view into business-critical signals like cart drop-offs or checkout failures. This leaves teams confident in system health while missing the issues that quietly erode revenue.
That’s why you need to know the best practices for Datadog in eCommerce environments.
Best Practices for Datadog in eCommerce Environments
Getting the most out of Datadog means shaping it around how your systems behave and how your teams work under pressure. These are the habits that keep your visibility sharp and your operations clean:
- Use tagging across all resources (for cost and clarity): Tag everything, such as services, environments, regions, and versions. That way, you can filter noise fast and track usage by team, product, or region. It also helps with budget ownership when teams share cloud accounts.
- Align alerting to error budgets, not just CPU spikes: System-level metrics aren’t enough. Instead of alerting every time a node spikes, tie your alerts to SLOs that actually reflect business health, like 99.9% payment success over 30 days.
- Make dashboards role-specific (DevOps ≠ Finance ≠ Support): Each team cares about different signals. Give Support user-level logs and error paths. Finance wants cost patterns. DevOps needs latency and deploy views. One dashboard doesn’t fit all.
- Review incident postmortems inside Datadog: Tag incidents, annotate timelines, and log what happened. Linking this back into Datadog helps close the loop. It’s how you stop repeat issues from slipping through again.
Now, let’s take a look at how you can keep all that visibility without letting Datadog costs spiral out of control.
Datadog Pricing & Cost Optimization Tips for eCommerce Companies
Understanding Datadog pricing starts with what you monitor. Costs scale by host count, custom metrics, containers, logs, and events. For example, the Pro tier gives you 100 custom metrics and 500 custom events per host, while containers beyond your plan get charged by the hour. It adds up quickly, especially with high-cardinality labels and noisy logs.
That’s why your first move should be tuning retention settings and using log rehydration instead of storing everything by default. So, you should keep what matters hot (basically keep critical data in fast-access storage) and archive the rest for when you need it. On top of that, cleaning up unused tags and reducing redundant metrics can cut bloat without losing visibility.
But storage isn’t the only place to cut waste.
Some teams also reduce spend by consolidating tooling. Instead of juggling five vendors for APM, logs, infrastructure, and uptime, moving those functions into Datadog usually lowers the overall bill. It also simplifies workflows as less integration overhead means faster onboarding for new team members.
The truth is, Datadog’s value comes from how well you manage what you send. Small changes in telemetry volume or tag sprawl can swing your invoice more than you might expect.
But if all this feels slightly overwhelming, let’s walk through how you’ll know when it makes sense to bring in an expert partner.
When to Bring in a Partner (Enter Nova)
There’s a point where scaling with Datadog alone starts to strain your team. That’s not a reflection of your skills but just the reality of managing high-volume, multi-cloud commerce systems. At some point, the return on self-management starts to shrink.
Here are the signs that it might be time to bring in a partner like Nova:
- You’re facing untracked cost spikes, or config overhead is slowing your team down.
- You need dashboard logic that works across business units (product, finance, support), not just infra views.
- You’re working with Kubernetes or Terraform and need proper integration across CI/CD or GitOps flows.
- You want a partner who understands commerce-specific metrics (from Stripe declines to supply chain lag) and builds systems around those signals.
But here’s the truth…
Getting Datadog to full maturity doesn’t have to mean hiring three new engineers or shifting attention away from feature work. In many cases, it just takes someone who knows the right trade-offs to make.
So, let’s take a look at how Nova actually delivers that kind of setup.
How Nova Implements Datadog for End-to-End eCommerce Visibility
Nova helps you turn Datadog into a system that tracks what matters (real customer behavior, not just infra metrics). From pipelines to payments, everything is instrumented with purpose. These are the key components of how we build that kind of observability.
Infrastructure as Code & Auto-Instrumentation
To make monitoring consistent across environments, Nova sets up Datadog using infrastructure-as-code tools like Terraform, Helm, and Kubernetes Operators. That gives you a repeatable, version-controlled deployment process for observability. This means no more manual steps or configuration drift between staging and production.
It also means you can validate changes to monitoring just like any other change in your stack. Going forward with this approach helps you enforce tagging standards, scale easily across accounts or regions, and reduce onboarding time for new services.
Whether you’re running on AWS, Azure, GCP, or a hybrid setup, you get the same baseline of telemetry from day one. And if you’re using Kubernetes, auto-instrumentation for logs, traces, and metrics can be baked into your deployment pipeline. That way, you never have to chase down missing data after something breaks.
Full-Stack Monitoring Configuration
Nova builds full visibility across your cloud infrastructure, applications, APIs, and external services. We help you instrument workloads across major platforms, as well as serverless functions like Lambda and Cloud Functions. That includes backend services, databases, and third-party tools like Stripe, PayPal, and Mulesoft, all wired into Datadog APM.
On top of that, our team configures RUM and Synthetic Monitoring to track user behavior, page performance, and API uptime. This end-to-end approach helps you trace a failed checkout or delayed confirmation from the frontend through the service mesh down to the API call.
It also cuts down MTTR by giving your engineers one place to correlate symptoms and causes, rather than bouncing between dashboards. That’s especially useful when your stack spans containers, VMs, and managed services.
CI/CD & Deployment Monitoring
Nova connects your existing pipelines (Jenkins, GitHub Actions, AWS CodePipeline, or GitOps workflows) into Datadog so you can monitor deploys in real time. You’ll be able to trace a bug or latency spike back to the exact commit or build job that introduced it.
We also configure rollout tracking, build duration monitoring, and error spikes tied to code pushes. That gives you visibility into key metrics like deployment frequency, failure rates, and MTTR without relying on separate release tools.
If a deploy goes sideways, your team gets alerted immediately based on error budgets or performance regressions. This lets you act quickly by pausing the pipeline, rolling back changes, and restoring service without digging through logs or CI history.
Custom Dashboards & Business-Centric Alerts
We help you build dashboards that are actually useful for each team, not just one-size-fits-all views.
- DevOps teams get infrastructure and deploy metrics.
- Product teams see user journeys and conversion paths.
- Finance can monitor cloud spend per product line.
That clarity also extends to alerting. Instead of just flagging CPU spikes, we configure alerts tied to business events like checkout failures or payment drop-offs. This ensures that incidents reflect real customer impact, not just noise.
To support fast resolution, we set up on-call rotations, auto-escalation policies, and alert routing across Slack, PagerDuty, and Opsgenie. Every alert links back to runbooks, so engineers know exactly what to do next. That way, alerts lead to action, not overload.
Security & Compliance Observability
Datadog already supports strong security features, but most teams don’t configure them fully. We make sure your data handling aligns with compliance needs from day one. That includes enabling audit trails, RBAC, and encrypted log storage across your environment.
Our team also maps monitoring workflows to common compliance frameworks like SOC 2, HIPAA, and PCI, which many commerce platforms are required to follow. In practical terms, that means logging sensitive activity like failed auth attempts or config changes, and keeping that data segmented and searchable.
Nova integrates security scanning tools with Datadog as well, so you can track vulnerabilities and patch status within the same view you use for deployments. This lets your team stay ahead of both technical debt and compliance risk.
Cloud Cost Monitoring & Optimization
Controlling Datadog and cloud spend usually comes down to visibility. Hence, we’ll set tagging standards that allocate usage by team, business unit, or customer segment so you see where the spend is going and why. That data rolls into live dashboards with clear summaries of service costs, volume spikes, and trends over time.
Our team also fine-tunes retention settings and log pipelines to keep costs lean. That includes downsampling non-critical logs, setting smart expiration rules, and rehydrating archived data only when needed.
For metrics, we help you reduce cardinality by redesigning tagging strategies and de-duplicating views. The goal is to cut noise and cost without losing context, so you keep what’s valuable and drop what isn’t.
eCommerce-Specific Visibility
You probably already know that eCommerce platforms bring their own mix of complexity, especially when you’re dealing with storefronts, payments, and logistics across multiple systems.
That’s why we focus on wiring up visibility where it matters most. That includes Salesforce Commerce Cloud, Shopify, and Adobe Commerce APIs, so you can monitor every step of the buyer journey.
We also trace transactions across Stripe, PayPal, and fulfillment tools like ShipStation or legacy ERPs. These integrations make it easier to pinpoint where failures occur, whether it’s a checkout delay or a payment gateway timeout.
With external service checks, we also track the health of third-party vendors like 3PL providers or inventory systems. When something breaks upstream or downstream, you don’t want to wait for user complaints. Instead, you’ll see early signs of lag, errors, or outages so you can act fast and protect revenue.
Nearshore Collaboration & Continuous Support
It’s no surprise that getting Datadog right takes more than just setup because it’s an ongoing process of tuning, scaling, and cost management. That’s why our nearshore team works in your time zone and alongside your engineers.
By staying close to your release cadence and deployment cycles, we can help you iterate faster and fix problems as they emerge. Whether it’s configuring SLOs, triaging incident alerts, or rewriting monitors for better precision, we handle the maintenance most teams struggle to keep up with.
We also help you build internal capability by documenting best practices and transferring knowledge during each sprint. From onboarding to daily optimization, the focus stays on supporting your team without slowing them down.
That continuity makes a big difference at scale, especially when pressure is high and priorities shift quickly.
Ready to Get More from Datadog?
Running Datadog in high-volume commerce environments takes the right setup, constant tuning, and sharp visibility into what matters most. That’s especially true when you’re balancing speed, cost, and uptime across a growing stack.
Whether you’re building new dashboards, tuning alerts, or scaling monitoring through Terraform, the details matter. The sooner you catch gaps or inefficiencies, the faster you can act on them before they cut into performance or revenue.
If you’d rather move faster with a partner who understands both the platform and the demands of digital commerce, schedule a call with Nova. We’ll help you get there.
Comments