
Retrieval-Augmented Generation on AWS Bedrock: Features, Use Cases, and More
TL;DR
- Retrieval-Augmented Generation (RAG) improves accuracy, compliance, and cost efficiency in enterprise AI by grounding model outputs in your verified data.
- AWS Bedrock makes RAG production-ready with managed orchestration, vector database integrations (Pinecone, OpenSearch, DynamoDB), and secure retrieval inside your AWS environment.
- Benefits of RAG on AWS Bedrock include:
- Accuracy: Reduces hallucinations and improves factual consistency by up to 30%.
- Compliance: Limits outputs to approved knowledge bases for audit-ready governance.
- Cost efficiency: Smaller models + retrieval = lower inference costs and latency.
- Scalability: Elastic workloads and automation through Lambda & Step Functions.
- Key use cases: Customer support automation, knowledge management, compliance reporting, healthcare Q&A, e-commerce personalization, and IT self-service.
- Implementation roadmap (7 steps): Define knowledge base → clean data → vectorize → retrieve → augment prompts → orchestrate → test & optimize.
- Nova Cloud advantage: As an AWS Advanced Tier Partner, Nova designs and implements Bedrock RAG architectures with compliance guardrails, Datadog monitoring, and proven cost-control strategies.
Turn your AI projects from experimental to production-ready. Book a Bedrock consultation with Nova Cloud today.
AI projects stall when models give answers that can’t be traced or trusted. That’s why you need outputs that are accurate, compliant, and cost-efficient.
This is where Retrieval-Augmented Generation changes the equation.
In this article, you’ll see how AWS Bedrock supports RAG with managed services, enterprise controls, and integration with knowledge bases.
But first, let’s look at what it is and how it differs from familiar search methods.
What Is RAG (Retrieval-Augmented Generation)?
Retrieval-Augmented Generation (RAG) links a document retriever with a large language model. The retriever pulls relevant information from your knowledge bases, and the model generates a response using that data.
This approach prevents answers built only on general training data and instead grounds outputs in your approved sources. Results include higher accuracy, stronger compliance, and more consistent performance across enterprise scenarios.
That’s why adoption is rising fast.
If you want to learn more, check out this YouTube video:
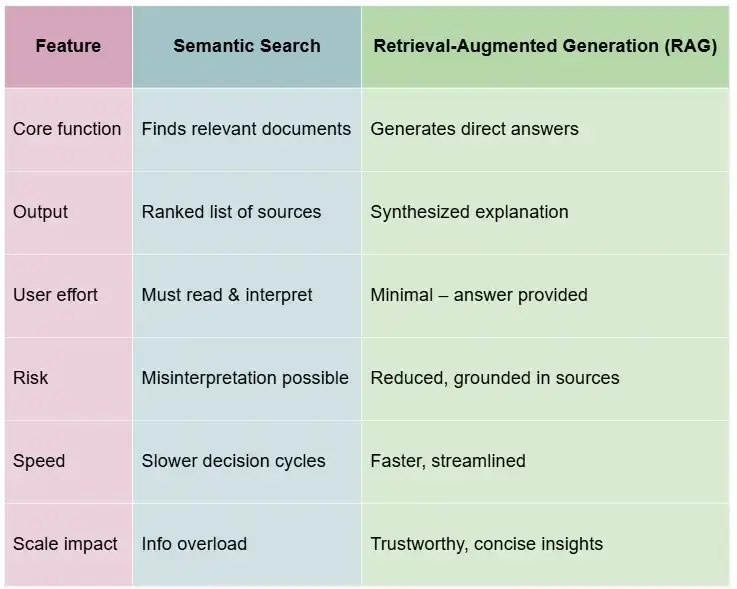
Retrieval-Augmented Generation vs. Semantic Search
Semantic search and Retrieval-Augmented Generation (RAG) solve related but very different problems.
With semantic search, you rely on vector representation to match queries against stored documents.
The system returns a ranked list of results, much like saying, “Here are three PDFs that probably contain your answer.” That helps you find information, but it still leaves the burden of reading, interpreting, and summarizing on your team.
RAG takes the next step.
Instead of only surfacing documents, it feeds the retrieved context into a generative AI model. The model then produces a synthesized answer that blends the query with the supporting evidence.
In practice, this means instead of handing you three policy PDFs, RAG generates a concise, human-readable explanation backed by those documents.
The gain is convenience, which directly:
- Reduces risks of misinterpretation
- Speeds up decision cycles
- Supports compliance by grounding answers in approved material
Pro tip: Nova Cloud helps you deploy Retrieval-Augmented Generation on AWS Bedrock to make your AI outputs auditable, accurate, and compliant from day one. Schedule a discovery call to find out how.
The difference matters at scale.
In an enterprise support setting, semantic search technologies alone might return dozens of troubleshooting guides. This will leave an engineer to piece them together manually.
RAG, by contrast, creates a direct response supported by those guides. That reduces handling time, improves retrieval accuracy, and gives your team an answer they can trust.
Next, let’s look at how knowledge bases shape RAG’s effectiveness.
Knowledge Bases in RAG
In RAG, a knowledge base is more than a storage system. It is a curated, domain-specific repository built from your policies, manuals, medical guidelines, or customer service history.
The strength of the answers you receive depends on the quality of this data. If you feed inconsistent or outdated information into the system, the model will generate outputs that carry the same flaws.
Garbage in still leads to garbage out.
To make this process efficient, text is vectorized into embeddings and stored in vector databases. When a query arrives, the retriever looks across this index to find the most relevant passages.
Unlike a generic search engine that matches keywords, vector-based retrieval captures meaning. This makes it better suited for enterprise scenarios where terminology is specialized. The indexing step ensures queries map correctly to the knowledge you approve for use.
Side note: For retailers, this same principle underpins personalized product discovery and transaction accuracy. And these are areas where Nova Cloud’s AWS retail solutions deliver measurable impact.
Why Foundation Models Need Help
The truth is, foundation models are trained on broad, public datasets. That gives them general fluency but leaves them exposed to gaps in domain knowledge and risks of hallucinations.
RAG supplies context that the model did not see during its original training because it bridges it with your structured knowledge base.
This has a measurable impact.
RAG models have achieved up to a 30% reduction in hallucination rates compared to traditional generative-only models. For industries under regulatory pressure, that difference reduces compliance risk and cuts verification workload.
When you ground answers in your own knowledge base, you get responses that reflect current policy, product data, or legal standards. The output is more accurate and auditable. That gives your teams confidence to use it in production settings without adding layers of manual oversight.
This helps us transition to…
Retrieval-Augmented Generation Benefits
RAG delivers practical advantages that offer more than just basic search or model outputs. Here are the benefits you gain by grounding large-scale artificial intelligence applications in structured retrieval.
Accuracy
When a model pulls responses directly from your approved documents, you reduce hallucinations and improve factual consistency. This difference is measurable.
For you, that means higher confidence in production workloads where even small errors can create compliance or operational risk.
Relevance
Retrieving from domain-specific content helps you be more sure that the generated text reflects your policies and systems rather than general internet data.
A similar principle is seen in ontology-guided RAG (OG RAG). Ontology-based retrieval further improves recall and fact-based reasoning.
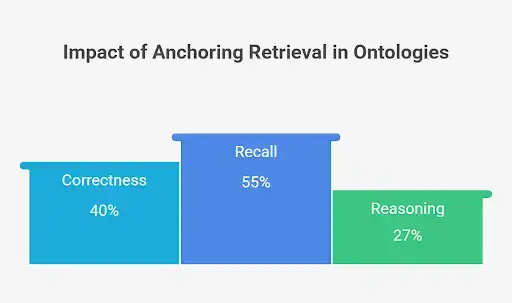
This is important if you want answers aligned to your enterprise vocabulary and workflows.
Compliance & Governance
Every enterprise system needs to limit responses to vetted knowledge. With RAG, you define the boundaries of the sources. This safeguards regulatory alignment and protects you from model drift into unverified information.
Cost Efficiency
RAG also lowers the total cost of inference. Smaller models can perform at a high level when retrieval is strong.
Research backs this up, showing that some models can cut costs by 97% and latency by 91% compared to GPT-3.5 and commercial frameworks. These savings help you free up budget for scaling workloads without expanding infrastructure spend.
Freshness
Since RAG queries updated knowledge bases, you avoid stale answers. A CMU study showed that combining multiple retrieval techniques greatly improves precision. That’s a sevenfold gain in precision, achieved by blending retrieval with generation.
Scalability
Finally, RAG extends across industries. Tests on biomedical data show that RAG can achieve strong accuracy even without fine-tuning
Results like these show that RAG can deliver high precision even without fine-tuning. That is why organizations in finance, healthcare, retail, and legal contexts are beginning to explore it as a scalable approach.
How Does Retrieval-Augmented Generation Work?
RAG follows a structured flow. Instead of relying only on a model’s original training, it adds your data to the process. These are the four steps that define how it works in practice.
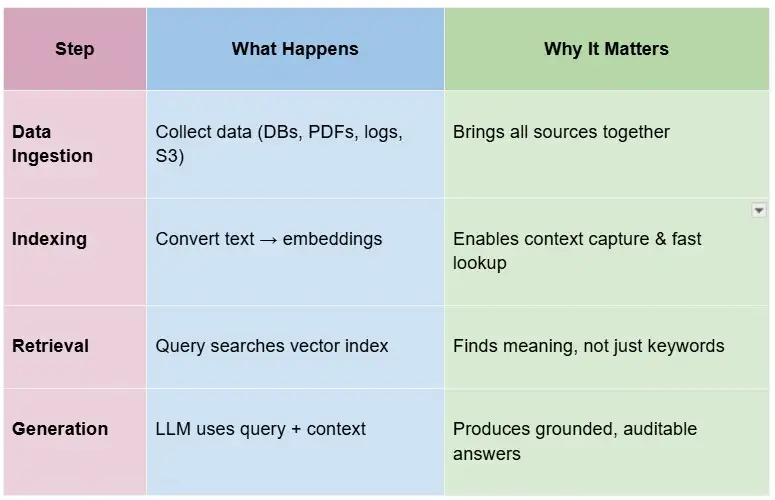
Data Ingestion
The first step is collecting data from different sources. You can connect structured repositories like databases or unstructured content like PDFs, transcripts, and logs. For enterprises, this usually means linking regulatory filings, product manuals, or data repositories stored in Amazon S3 or similar systems.
Indexing
Next, the system processes that content into embeddings. Text is converted into dense vectors that represent meaning instead of raw keywords. This allows the retriever to capture context more effectively. Indexing also enables fast lookups through a vector database, so a query can map directly to the right passage.
Retrieval
When a user submits a query, the retriever searches against the vector index. Instead of scanning everything, it pulls the top results that match the query’s context. This step is where RAG differs from traditional search index approaches, since you’re comparing meaning rather than surface-level matches.
Generation
Finally, the retrieved context is passed to a large language model. The model blends the query and retrieved text to generate an answer. This grounding reduces hallucinations and makes outputs auditable.
In healthcare, a study on preoperative medicine showed that RAG lifted accuracy to 91.4%, surpassing the human baseline of 86.3%. That’s an 11.3-point improvement with direct clinical value.

This structured loop is the foundation that makes RAG practical at enterprise scale. Now, let’s see how AWS Bedrock adds managed capabilities to streamline these steps.
Retrieval-Augmented Generation on AWS Bedrock
RAG becomes far more practical when combined with managed cloud services. AWS Bedrock provides the infrastructure, orchestration, and integrations needed to operationalize it. Here are the key features, comparisons with open-source stacks, and use cases that show how it works in enterprise settings.
Key Features of AWS RAG on Bedrock
AWS Bedrock gives you a managed foundation for running Retrieval-Augmented Generation at a production scale. Instead of assembling individual services yourself, you can rely on native features that streamline setup and reduce operational risk.
These are the capabilities that matter most:
- Amazon knowledge bases integration: Bedrock connects directly with your structured repositories, which removes the need to build your own ingestion pipelines. This simplifies knowledge base preparation and reduces engineering overhead.
- Choice of foundation models: You can select from Anthropic, Cohere, or Amazon Titan models depending on your workload. This flexibility helps you align compute cost and accuracy with the specific use case.
- Vector store options: Bedrock supports Pinecone, OpenSearch, and DynamoDB as retrieval backends. You decide how to manage embeddings while staying inside the AWS ecosystem.
Pro tip: To see how this works in practice, check out our case studies. We’re discussing how we helped companies implement AWS solutions successfully from problem to results.
And we have plenty of examples and diagrams to help you get started as well.
- Private and secure retrieval: Data never leaves your AWS environment. This matters when you are subject to compliance audits or working with regulated workloads.
- Orchestration support: With Step Functions and Lambda, you can control workflows around ingestion, retrieval, and generation without stitching together external schedulers.
- Elastic scaling: Bedrock workloads scale automatically with traffic. That means you avoid overprovisioning during quiet periods and still maintain low latency during peak demand.
Amazon Bedrock vs. Unstructured
When you evaluate RAG in production, the decision usually comes down to whether you assemble an open-source stack or use a managed platform like Amazon Bedrock. Each option has tradeoffs you need to weigh.
Here’s what our team noticed with Bedrock:
- You gain managed infrastructure, model choice, and integration across the AWS ecosystem.
- You don’t have to configure your own retrievers or build orchestration layers from scratch.
Bedrock supports Amazon Knowledge Bases, integrates with DynamoDB or OpenSearch for retrieval, and connects with Lambda and Step Functions for workflow control. That means your engineering team spends less time on glue code and more time on use-case delivery.
In contrast, we admit that an unstructured stack (built with LangChain, LlamaIndex, FAISS, and Pinecone) offers more flexibility.
The problem is that it demands greater engineering overhead. You need to design the retrieval layer, manage embeddings, and handle scaling yourself.
This path works if you’re running small pilots or testing edge research ideas. We don’t recommend it to companies that move to regulated production workloads, though.
That’s because it adds more risk.
In cases like this, you’re responsible for compliance guardrails, latency tuning, and cost monitoring across services.
The truth is that Bedrock gets you to enterprise readiness faster. It reduces the total cost of ownership by removing infrastructure management and gives you compliance support out of the box. The open-source path is best for experimentation, while Bedrock is designed for teams that need predictable performance, governance, and scale.
Read more: Cost and compliance typically go hand in hand with licensing. If you’re also watching VMware changes, our breakdown on how 2025 licensing shifts impact infrastructure strategy shows where to expect budget pressure.
Use Cases of Retrieval-Augmented Generation on AWS Bedrock
Bedrock allows you to operationalize RAG at scale with managed services and integrated orchestration. These are the enterprise use cases where the platform delivers measurable value:
- Customer support automation: With Bedrock, you can connect manuals, order histories, and policy documents stored in S3 or Simple Storage Service into a knowledge base. This allows AI assistants to generate accurate responses rather than sending users through endless search results. The reduction in manual lookups lowers ticket resolution time and improves satisfaction.
- Research and knowledge management: You can query across millions of files, journals, or technical docs. Bedrock’s integration with vector databases like OpenSearch supports retrieval at scale, while orchestration with Step Functions enables fast content generation pipelines.
- Compliance and risk: Responses are limited to your vetted data sources, which support audits and regulatory standards. Enforcing source restrictions allows you to reduce liability from answers generated outside approved frameworks.
- Healthcare: Bedrock can serve clinical teams by grounding outputs in updated guidelines and case histories. With question-answering systems, the model provides synthesized recommendations that are accurate and verifiable.
- E-commerce: Personalized product Q&A becomes practical when Bedrock retrieves from catalog metadata and user activity. You cut down on abandoned carts by guiding buyers with context-rich answers.
- Internal IT helpdesk: Bedrock automates Level 1 troubleshooting by pulling from system documentation, integration playbooks, and access workflows. Engineers save time on repetitive queries and focus instead on higher-level issues.
Moving on, let’s see how to implement these workflows step by step.
Read more: Scaling retrieval isn’t just a data problem. Retailers face the same challenge as they expand cloud use. Here’s how top AWS migration partners are helping IT teams reduce risk while scaling knowledge access.
How to Implement RAG on AWS Bedrock
Moving from concept to production requires a structured plan. Bedrock provides managed components, but you still need to design the workflow carefully. These are the steps you should follow when implementing Retrieval-Augmented Generation in your environment.
Step 1: Set Up Your Knowledge Base
The foundation defines where your model will pull context from. In Bedrock, you use Amazon Knowledge Bases to ingest data sources such as S3 buckets, relational databases, APIs, or static documents like PDFs.
The key decision here is scope.
After all, you want to include enough content to support your use cases without adding unnecessary noise.
For example, in a financial institution, you might prioritize regulatory filings and compliance manuals over general marketing material. The better your training data sources, the more reliable the retrieval results.
Step 2: Data Preparation & Cleaning
Next, you need to prepare and normalize the data. Formats can vary, such as JSON, CSV, text, and proprietary document types. And they all require consistent structuring.
Deduplication and redaction are also important.
Leaving duplicates wastes storage and retrieval cycles, while failing to scrub sensitive data may expose confidential information.
Curating your knowledge base before indexing allows you to reduce the likelihood of spurious responses and improve grounded generation.
Step 3: Vectorization
Once data is ready, Bedrock models convert text into embeddings. This step transforms raw sentences into vector space representations that capture meaning instead of surface keywords.
Here’s an example:
You then store these embeddings in Amazon Knowledge Bases or integrated vector stores like OpenSearch. The model you choose for embedding impacts retrieval performance.
A stronger embedding model improves semantic matching, while poor embedding quality leads to irrelevant context retrieval. In practice, teams usually run pilots comparing multiple embedding models to see which balances cost with retrieval precision.
Step 4: Retrieval Layer
The retrieval layer defines how the system pulls passages when a query arrives. You configure parameters like top-k (number of passages retrieved) and similarity thresholds. Bedrock integrates with services like Pinecone or DynamoDB for this search.
The good news is that you can find plenty of tutorials to start using these tools:
You should also design caching strategies to lower latency on repeated queries. In regulated industries, retrieval must also log the documents selected to enable source attribution when answers are audited.
If retrieval is too loose, you risk hallucinations. But if it is too strict, you may miss relevant context. Careful relevance tuning here drives accuracy downstream.
Step 5: Prompt Augmentation
Retrieval alone doesn’t complete the pipeline. You need to feed the retrieved content into the prompt engineering process for the model. Bedrock allows you to inject retrieved context directly into the prompt, which will then guide the model to answer only from the provided sources.
A common template is: “Answer based only on the following documents: [docs]. If the answer is not contained, respond that it is not available.”

Our experts use this approach to:
- Constrain the model’s behavior
- Reduce hallucination risk
- Makes outputs more auditable
Prompt design should become part of your compliance control, since it dictates how the model interprets user input.
Step 6: Automation & Orchestration
For production deployments, orchestration is important.
AWS Lambda and Step Functions let you automate ingestion, retrieval, and generation workflows. For example, you can trigger a Step Function whenever new documents are uploaded to S3 to ensure the knowledge base stays current.
Monitoring is equally essential.
Bedrock integrates with CloudWatch, and you can extend this with Datadog to track latency, error rates, and cost metrics. Without monitoring, you risk silent failure where the system appears functional but produces incomplete retrievals.
Automation ensures repeatability, while orchestration prevents gaps across steps.
Pro tip: Visibility gaps can derail even the best automation. Our Datadog-powered DevOps guide shows how to monitor eCommerce stacks without leaving blind spots.
Step 7: Testing & Optimization
Finally, you evaluate the pipeline under realistic workloads. Testing should cover accuracy, latency, and cost.
For accuracy, you can benchmark responses against human-curated answers. Latency testing should measure performance under concurrent question-answering systems or chatbot interactions. Cost analysis involves tracking retrieval and inference charges under projected query volumes.
Remember: Over time, you’ll need to refresh the knowledge base.
Content ages quickly in industries like healthcare or finance, so ongoing updates keep the system aligned with current policy. Continuous evaluation is how gains made at launch persist at scale.
Pro tip: Optimization doesn’t end with testing. Many enterprise teams use specialized AWS cloud optimization consultants to tune workloads further. Here’s who’s helping CPG and retail teams scale smarter.
Let Nova Tackle Your RAG on AWS Bedrock
Building RAG on AWS Bedrock takes more than connecting services. You need an architecture that balances accuracy, governance, and cost from day one.
Nova is an AWS Advanced Tier Partner with expertise in Bedrock, Datadog, and enterprise cloud engineering.
That means you gain a team that has deployed large-scale machine learning and AI solutions in regulated industries where compliance and reliability cannot be optional.
Clients choose Nova because the time to value is faster.
Instead of spending months stitching orchestration together, you work with engineers who already know how to align Bedrock with knowledge bases, monitoring, and security controls.
You also avoid the risk of deploying a fragile stack that scales poorly.
Every architecture is built with compliance guardrails and financial efficiency in mind, so you get an implementation tuned to your business rather than a generic template.
If you are evaluating RAG for production, Nova helps you move from pilot to full-scale rollout without wasted cycles. Schedule a call today to explore a proof of concept or design an enterprise deployment that fits your roadmap.
Share this article
Follow us
A quick overview of the topics covered in this article.




